on
Tython: Python에 Typing 얹기

Python은 강타입 언어입니다. 서로 다른 타입 간의 연산이 금지되어 있고, 타입 변환을 위해서는 명시적으로 형변환을 해주어야 합니다.
하지만 C언어와 같이 변수의 데이터 타입을 명시적으로 지정하는 정적 타이핑 언어(Static Typed)가 아닙니다. 파이썬은 동적 타이핑 언어(Dynamically Typed)로, 한 변수에 할당된 데이터와 다른 타입을 가진 데이터를 언제든지 재할당할 수 있습니다.
a 라는 변수에 string 데이터를 할당한 이후 언제든지 int, string[] 등의 다른 타입의 데이터를 재할당할 수 있다는 것입니다.
타입을 지키지 않아도 코드 실행에 문제가 없다는 장점 덕분에 극한의 생산성을 발휘해내야 하는 해커톤, 빠르게 제품을 런칭해야 하는 스타트업에서 사용하기 좋은 특성을 가지고 있습니다.
하지만 서비스를 안정적으로 운영해야 하는 환경에 놓여 있다면, Python의 동적 타이핑 특성은 너무나 큰 장애물입니다. 실제로 문제가 있는 코드라면 런타임 환경에 가서야 터지기 때문이죠.
🧐 그래서 저희 코드 베이스는..
Any type이 넘쳐나고, 2,000개가 넘는 파일에서 약 20,000개의 type error가 발생하고 있었습니다.
Python은 parameter와 return type의 type definition을 강제하지 않으니, 깨진 유리창은 계속 깨져만 갈 뿐이었습니다.
다른 개발자가 정의해놓은 type definition이 있으면 신나게 Type Hint의 도움을 받아 코드를 작성하기도 했지만, 잘못된 type definition을 작성해두었거나 outdated 정보가 적혀있는 경우도 많았습니다.
실제 argument로 넘겨주는 데이터의 type과 parameter에 정의된 type이 달라도 에러가 발생하지 않았습니다.
def execute_meeting(id: str) -> None:
pass
execute_meeting(11) # actual: [int], expected: [str]
실제 return하는 데이터의 type과 return type이 달라도 에러가 발생하지 않았습니다.
def extract_company_name(foo: str) -> str:
return re.match(r"bar", foo) # actual: [str | None], expected: [str]
단순한 오타도 인해 존재하지 않는 속성에 접근하는 경우도 마찬가지였습니다.
@dataclass
class User:
id: int
full_name: str
dongzoo = User(id=1, full_name="dongzoolee")
dongzoo.full_naem # "User" has no attribute "full_naem"
그리고, 이 오류들을 전부 사람이 완벽하게 판단해내거나, 리뷰어가 육안으로 발견해내기에는 어려움이 있었습니다.
저희 팀은 Static Type Checker 도입의 필요성을 뼈저리게 느꼈습니다.
1️⃣ mypy 도입의 시작
1년 전 이 날은 객체에 존재하지 않는 속성에 접근하는 코드로 인해 버그가 발생하여 핫픽스 패치를 넣은 날이었습니다.
QA 단계에서 잡히지 않았다는 점도 문제이긴 했지만, 저는 다른 Static Typed Language라면 발생하지 않았을 문제라고 생각하여 바로 Static Type Checking 툴을 찾아보았습니다.
그리고 mypy 라이브러리를 도입하기로 결정했습니다.
그 당시에는 아직 0.9xx 버전 밖에 릴리즈되지 않은 상태였지만, Python 재단에서 직접 관리하는 라이브러리라는 점이 큰 신뢰감을 안겨주었습니다.
mypy를 dev dependency에 추가하고, 저희 프로젝트에 맞는 config를 작성하여 도입 준비를 마쳤습니다.
# pyproject.toml
[tool.mypy]
python_version = "3.11"
exclude = "DIRECTORIES_TO_EXCLUDE"
plugins = ["mypy_django_plugin.main"]
enable_incomplete_feature = ["Unpack"]
ignore_missing_imports = true
disallow_untyped_defs = true
check_untyped_defs = true
local_partial_types = true
warn_unused_ignores = true
warn_redundant_casts = true
VSC를 사용하고 있는 저희 팀원들 모두 mypy extension을 설치하여 에러를 IDE에서 직접 눈으로 확인할 준비까지 마쳤습니다.
당시만 해도 Microsoft 공식 mypy extension이 없었는데 올해 4월에 Microsoft에서 공식 extension을 출시했습니다. 사용해보지는 않아서 두 extension의 차이는 잘 모르겠지만 아직 Preview 뱃지가 붙어 있네요.
난항
위에서 언급했다시피, 저희 코드 베이스에서 mypy 에러가 발생하는 파일의 수는 2,000개가 넘었습니다.
감당할 수 없는 에러의 숫자로 IDE는 빨간불에 뒤덮히기 시작했습니다.
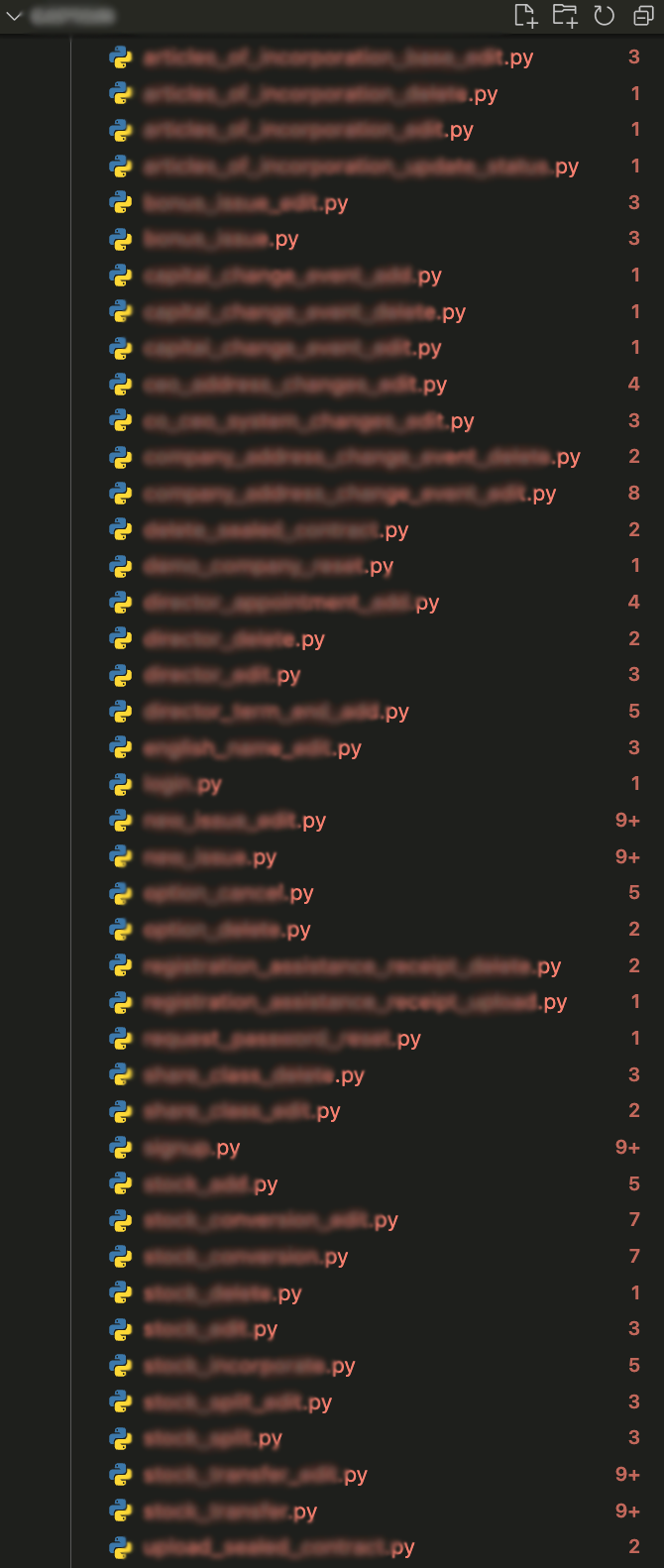
거의 모든 파일과 line에 빨간불이 들어오니 절대로 해결할 수 없는 문제들처럼 보였고, mypy 또한 성능 저하를 일으켜 당장에 작성하고 있는 코드의 type error를 확인하는 데에도 약 10-20초 이상이 소요되었습니다.
심지어 vim에서는 렉이 너무 심하여 작업이 아예 불가능했습니다.
팀원들은 하나 둘 mypy extension을 제거하기 시작했습니다.
점진적 리팩토링의 실패
에러 코드별로 에러가 발생하는 파일들의 목록을 정리해놓고 팀원들과 매일매일 파일 1개씩 담당하여 type error를 수정하기로 했습니다.
수정이 완료된 에러 코드들을 하나씩 CI Check에서 활성화하여, 궁극적으로는 모든 에러 코드들을 CI에서 활성화시키자는 취지였습니다.
약 3달 간 리팩토링을 진행했지만 승산은 없었습니다.
type error를 수정하려면 각 파일의 로직을 이해하고 있거나 이해하는 데에 시간을 사용해야 했는데, 이 비용은 팀원들에게 꽤 비쌌습니다.
근본적으로는 작업량이 너무 방대했습니다. 점진적 리팩토링은 실패로 돌아갔습니다.
이전 것들은 묻고, 새로 시작하자
현재 발생하는 모든 type error를 전부 묻어버리고, 앞으로 추가되는 코드부터 type error를 검사하자는 발상입니다. 지금이라도 mypy를 활성화하지 않으면 type error가 평생 무한히 늘어나기만 할 것이기 때문이죠.
그런데 이 묻어버리는 과정을 어떻게 실행할 것인가가 문제였습니다.
Mypy는 type error를 무시하는 방법으로 아래 세 가지를 제공합니다.
- 검사에서 제외할 directory를 config file에 정의하기
- 검사에서 제외할 파일의 상단에
# mypy: ignore-errorscomment 추가하기 -
에러가 발생하는 line에
# type: ignorecomment 추가하기# type: ignore는 Python에서 type error ignore를 도와주는 magic comment입니다.에러가 발생하는 line의 오른쪽에
# type: ignorecomment를 붙여주면 mypy가 해당 line의 type error를 검사하지 않습니다."string" + 1_000 # type: ignore[]에 에러 코드를 넣어주면 해당 에러 코드만 검사하지 않도록 할 수도 있습니다."string" + 1_000 # type: ignore[wrong-concatenation]
회사 동료인 @tonynamy는 3번의 방법에 주목했습니다. 바로 type error가 발생하는 모든 line에 각 에러 코드에 맞는 # type: ignore[...] comment를 달아버리는 것입니다.
Mypy 실행 결과로 출력되는 에러가 발생한 파일 경로, 줄 번호, 에러 코드를 파싱하여 해당 위치에 # type: ignore[...] comment를 붙여주는 스크립트를 작성하여, 저희 코드 베이스에 실행하셨습니다.
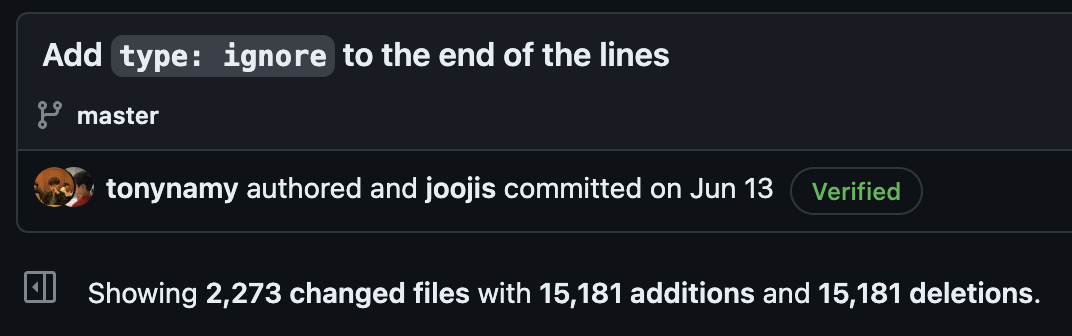
제가 작업한 스크립트를 오픈소스로 공개해달라고 요청했는데, 아직 공개하시진 않았습니다 😅
Good Boy scouts 😎
위 패치가 머지된 이후, CI에서 모든 Mypy 에러를 검사하기 시작했습니다. 이제는 Mypy 에러가 발생하는 코드가 master 브랜치에 머지될 수 없습니다. 깨어진 유리창이 더 조각나는 일은 더이상 발생하지 않는 것이죠.
그리고 본인이 다루는 레거시 코드에 # type: ignore comment가 붙어 있다면, 일단 해당 부분의 type error들을 전부 해결하고 작업을 시작하고 있습니다.
착한 보이 스카우트 팀원들 덕분에 # type: ignore comment는 매일매일 정말 빠른 속도로 줄어들고 있습니다.
2️⃣ 구원자 typed-graphene
Graphene은 Python에서 GraphQL Schema와 Type을 편리하게 작성할 수 있도록 도와주는 라이브러리입니다.
그런데, 저희가 사용하고 있는 이 라이브러리의 제일 큰 단점이 있습니다.
바로 Python native type(str, int, [], …), dataclass, TypedDict를 사용하여 Schema를 정의할 수 없다는 점입니다. 다시 말해, Graphene에서 제공하는 Scalar class(String, Int, List, …)를 사용하여 Schema를 정의해야 한다는 것인데, 이 Scalar class들은 Mypy에서 전부 Any로 평가되는 문제가 있습니다.
(사실 저희 코드 베이스에 Any type을 난무하게 만든 주범은 Graphene입니다)
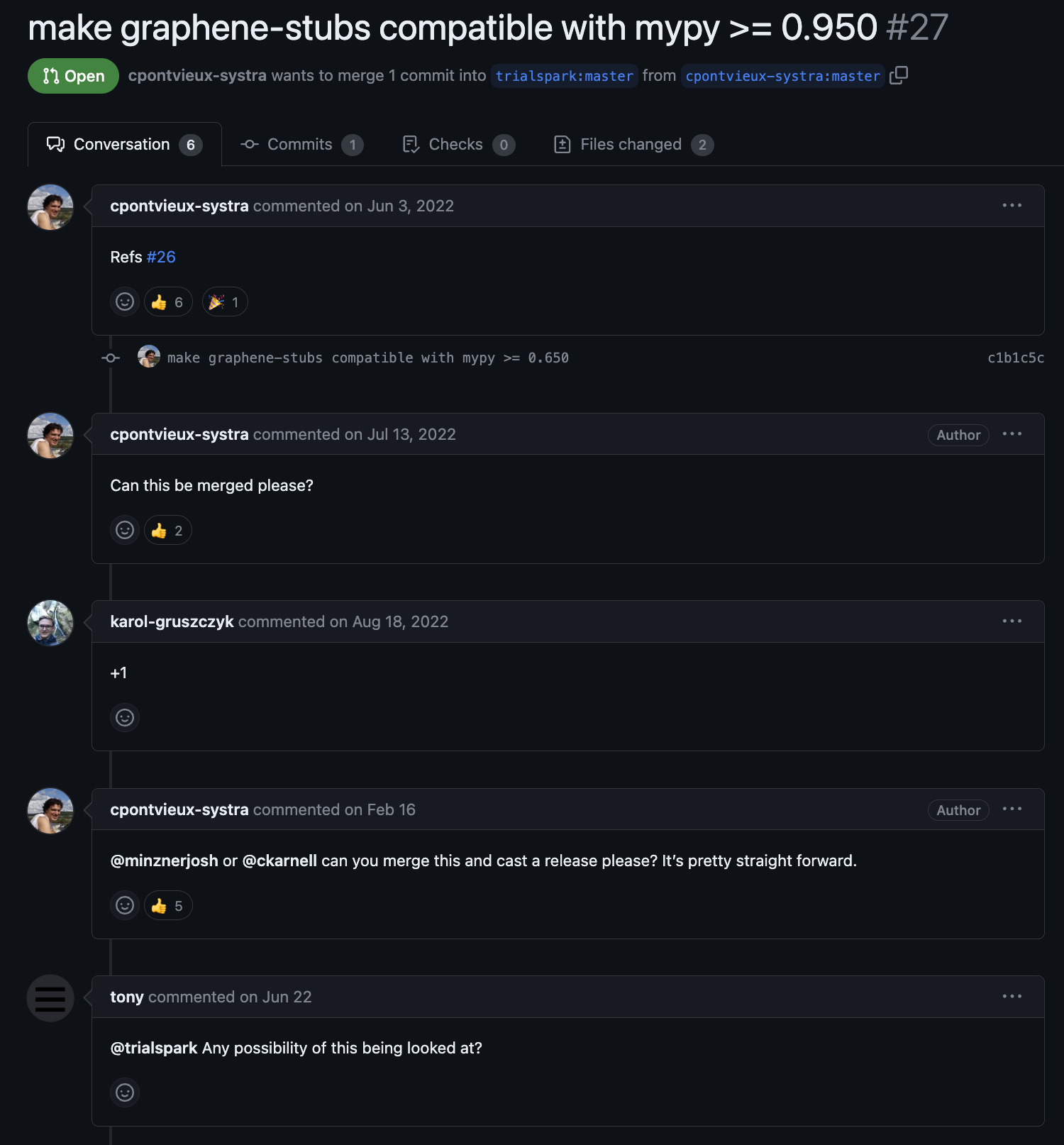
관련 이슈도 있었지만, 타이핑 지원 계획은 전혀 없어 보였습니다.
https://github.com/graphql-python/graphene/issues/966
이를 해결하기 위해 한 개발자가 타입 패키지를 만들었지만, 해당 패키지 개발자는 고장난 패키지를 방치해둔채로 손을 떼버렸습니다.
https://github.com/trialspark/graphene-stubs
Graphene의 문제를 완전히 해결한 Strawberry라는 라이브러리가 등장했지만, 현재 저희 프로젝트는 너무나 많은 Schema와 Type들이 Graphene으로 작성되어 있어 migration이 거의 불가능한 수준이었습니다.
https://github.com/strawberry-graphql/strawberry
어느날 회사 동료인 @tonynamy님께서 Graphene에서 Python native type, dataclass, TypedDict를 사용하여 GraphQL Schema를 만들 수 있도록 도와주는 typed-graphene이라는 패키지를 들고 왔습니다.
https://github.com/tonynamy/typed-graphene
아래 After 코드를 보면, graphene으로부터 아무 것도 import 하지 않고 Python native type만 정의해서 Schema를 작성해나갈 수 있음을 확인할 수 있습니다.
Before: w/Graphene
from graphene import Field, Int, ObjectType, String
class UserType(ObjectType):
id = Int(required=True)
full_name = String(required=True)
age = Int()
class UserQuery:
user = Field(UserType, required=True, id=Int())
def resolve_user(self, info, **data) -> UserType:
data["id"] # [Any]
return UserType(
id=...,
full_name=...,
age=...,
)
After: w/TypedGraphene
from dataclasses import dataclass
from typing import TypedDict, Unpack
from typed_graphene import TypedField
@dataclass
class UserType:
id: str
full_name: str
age: int | None
class UserFieldArguments(TypedDict):
id: int
class UserQuery:
user = TypedField(UserType, **UserFieldArguments.__annotations__)
def resolve_user(self, info, **data: Unpack[UserFieldArguments]) -> UserType:
return UserType(
id=...,
full_name=...,
age=...,
)
typed-graphene 덕분에 GraphQL Schema의 모든 Argument와 Field의 타이핑이 가능해졌습니다.
약 4달 전부터 작성된 GraphQL Query, Mutation, Type들은 전부 typed-graphene 패키지를 사용하여 작성되고 있습니다. 타이핑이 100% 지켜진 상태로 말이죠.
😉 이외에도
도저히 고쳐지지 않는 type error를 가진 외부 라이브러리를 직접 wrapping하여 강제로 type casting한 후 사용하기도 하고, 직접 외부 라이브러리의 stub 패키지를 제작하여 사용하기도 합니다.
😅 물론 아직은
TypeScript와 동작이 완전히 동일하지는 않습니다. 저를 포함한 많은 팀원들이 엄격한 타입 체킹의 늪에서 매일매일 발버둥치고,, 또 발버둥치고 있습니다.
그리고 pip에 등록된 많은 라이브러리들이 타입 패키지(stub)를 공식적으로 지원하지 않습니다.
Mypy 또한 TypeGuard가 이제 막 지원되기 시작했고, TypedDict의 type narrowing 기능도 아직은 걸음마 수준입니다. 그렇지만 Mypy는 거의 2-3주에 한 번씩은 신규 버전을 출시하는 등, 굉장히 빠른 발전을 보이고 있어 이 정도 불편함은 잠시 안고 가도 괜찮겠다는 생각을 하고 있습니다.
👋🏼 마무리하며
TypeScript 혹은 Mypy의 type check를 통과하는 fully type-safe한 코드를 작성하기 위해서는 그렇지 않을 때보다 1.5배 정도의 노력을 더 써야합니다. 실제로 type error를 고치기 위해 고생하다가 개발 일정에 차질이 생기는 경우도 다반사입니다.
특히나 기존에 잘 작동하던 코드에 Generic을 추가하기라도 하면 여기저기에서 type error가 발생하는 것은 일도 아닙니다.
ZUZU에서는 JSX → TSX 마이그레이션, Graphene → TypedGraphene 마이그레이션, Mypy 타입 에러 수정 등 Type 관련 귀찮은 과제들을 해결하느라 꽤나 땀을 흘렸고 끝없이 땀흘릴 예정이지만, 제품 초기부터 완벽한 코드를 고집하며 개발을 했었다면 아마 제품을 시장에 내놓지도 못 하고 개발만 하다가 끝나 버렸을 수도 있습니다.
가끔은 밉기도 한 완벽하지 않은 코드들 덕분에 빠르게 서비스를 런칭하고, 생산성 높은 개발을 할 수 있지 않았나 싶습니다.